AI Context Versioning Best Practices for Dev Teams
Discover essential AI context versioning best practices to safeguard your projects. Learn how to manage prompts effectively and ensure stability.
ClaudeDrive
A Yungsten Tech product

AI Context Versioning Best Practices for Dev Teams

AI context versioning is the practice of managing prompt templates, system instructions, tool contracts, and policy configurations as immutable, versioned software artifacts with full deployment controls. Without it, a single untracked edit to a production prompt can silently change AI behavior across thousands of requests, with no audit trail and no fast path back to stable. The industry term for the broader discipline is context lifecycle management, and the ai context versioning best practices covered here apply whether you’re running a single Claude-powered feature or a fleet of autonomous agents. Platforms like Portkey and Langfuse have added versioning primitives, and frameworks like Agent Patterns and Contextarch have formalized the standards. This article gives you the practical list.
1. AI context versioning best practices start with immutable artifacts
The single most important rule in production AI context management is this: once published, never edit. A prompt version that reaches production becomes a read-only artifact. Any change creates a new version ID. This rule eliminates an entire class of incident where a quick in-place fix introduces a regression that nobody can trace because the original state no longer exists.
The practical implication is that your storage layer must enforce immutability, not just encourage it. A database row with an "updated_at` column is not a versioning system. A content-addressed store or an append-only registry with pinned version IDs is.

Pro Tip: Tag every published version with a semantic version number (e.g., prompt-customer-support:2.1.0) so your deployment pipeline can reference it deterministically. Semantic versioning communicates the scope of change to reviewers before they read a single line.
2. Treat context as code with atomic changes and full metadata
The Context as Code framework from Contextarch defines what disciplined versioning actually requires: atomic changes, preserved history, mandatory testing gates, and tracked metadata. Each version record should carry at minimum:
- Author and timestamp
- Dependency references (model version, tool schema version, policy config version)
- Environment compatibility (staging vs. production)
- Linked test results and evaluation scores
- Rationale for the change
Treating context as code means your Git repository holds the source of truth, your CI pipeline runs evaluations before merge, and your deployment system promotes artifacts through environments rather than copying text between dashboards. The discipline prevents shipping partial or conflicting context, which is the most common source of hard-to-reproduce AI behavior bugs.
3. Version everything, not just the prompt
Versioning only the prompt is incomplete. Tool schemas, policy files, and runtime configuration all affect AI behavior. A prompt that worked perfectly with tool schema v1.2 may produce malformed calls against tool schema v1.3. If you only version the prompt, that regression is invisible until it hits users.
The minimum viable versioning scope for any AI agent or context-driven feature includes:
- Prompt templates and system instructions
- Tool contracts and function schemas
- Policy and guardrail configuration files
- Model version pin (e.g.,
claude-3-5-sonnet-20241022) - Retrieval configuration (index version, chunk size, similarity threshold)
- Runtime environment compatibility tag
Agent Patterns calls this a complete environment snapshot, and it’s what makes incident investigation tractable. When something breaks, you can replay the exact execution environment from the version manifest rather than reconstructing it from memory.
4. Use version manifests with hash-based integrity checks
A version manifest is a single file that records the hash of every artifact in a release: prompt, tool contracts, policy config, and environment pin. The runtime reads this manifest at startup and refuses to start if any hash mismatches. This prevents the common failure mode where a deployment script updates one artifact but not another.
The Agent Patterns governance model specifies that runtime starts only with a pinned version_id, which enables both reproducibility and post-incident forensics. If a user reports unexpected behavior on Tuesday afternoon, you pull the version manifest that was active at that time and you know exactly what ran.
This approach also makes audits straightforward. Compliance teams can verify that a specific policy configuration was active during a specific window without relying on anyone’s memory or manual logs.
5. Deploy with canary rollouts and quality-based triggers
Canary deployments for AI context start at 1% of traffic, then scale through 5%, 20%, and 100% as quality metrics hold. The key distinction from infrastructure canaries is that the rollback trigger is a quality regression, not a latency spike or error rate. Format validity dropping below 95%, semantic correctness scores falling against a golden dataset, or escalation rates rising above baseline are all valid rollback signals.
“Quality regression evaluation matters more than infrastructure metrics for detecting prompt failures in production.” — Tianpan canary rollout guidance
The traffic slice progression gives you real signal at low blast radius. A prompt that looks fine in staging may fail on a specific distribution of production inputs that your test set doesn’t cover. Canary rollouts surface that failure before it affects the majority of users.
Pro Tip: Define your rollback thresholds before you start the rollout, not after you see a problem. A threshold set under pressure will always be too lenient.
6. Implement rollback as a pointer switch, not a redeploy
Rollback speed matters under production load. Rollback via pointer or alias switch to an immutable previous version takes seconds. A full redeploy can take minutes, and under traffic pressure those minutes compound into significant user impact.
The mechanism is simple: your deployment system maintains a production alias that points to a version ID. Rolling back means updating that alias to point to the previous stable version ID. No artifact moves, no pipeline reruns, no risk of introducing a new error during the recovery process.
This is only possible if your artifacts are truly immutable. If you’ve been editing versions in place, the “previous version” may not be the state you think it is. Immutability and fast rollback are the same requirement expressed from different directions.
7. Enforce branching and peer review for all context changes
Context development is a team sport involving domain experts, AI engineers, and QA testers. A solo developer editing a system prompt in a web UI and clicking save is the equivalent of pushing directly to main with no tests. The outcomes are predictably similar.
Effective collaboration on AI context requires:
- Feature branches for every change, no matter how small
- Pull requests with mandatory automated evaluation gates before merge
- Reviewers from at least two roles: the person who owns the domain and the person who owns the model behavior
- Documentation of scope, rationale, and linked evaluation results in every PR description
Context-aware merge tooling matters here. Standard text diff tools show you what changed in a prompt, but they don’t show you whether the semantic meaning shifted. Pairing text review with automated evaluation scores gives reviewers the signal they need to approve or reject with confidence.
Pro Tip: Require that every PR description answers three questions: what changed, why it changed, and what the evaluation scores show. Teams that skip the “why” create a context history that’s traceable but not understandable.
8. Build continuous quality monitoring with golden datasets
Post-deployment monitoring for AI context is different from standard application monitoring. Response latency and error rates tell you almost nothing about whether the AI is producing correct, on-policy outputs. You need golden datasets evaluated by LLM judges running continuously against production traffic samples.
| Metric | What it detects | Recommended threshold |
|---|---|---|
| Semantic correctness score | Meaning drift from expected outputs | Alert below 0.85 |
| Format validity rate | Structural regressions in structured outputs | Alert below 95% |
| Hallucination rate | Factual accuracy degradation | Alert above baseline + 2% |
| Escalation or clarification rate | Confidence or scope regression | Alert above baseline + 5% |
Golden datasets need regular updates. A dataset built at launch will gradually lose coverage as production inputs evolve. Schedule quarterly reviews of your golden set and add cases from any incident or near-miss. The dataset is a living artifact and should be versioned alongside your context artifacts.
9. Manage context drift with scheduled review cycles
Environment-driven drift is a real risk in production AI systems. A model provider updates a base model, a downstream API changes its response schema, or your knowledge base grows stale. None of these trigger an alert in a standard monitoring system, but all of them can degrade AI behavior over time.
Scheduled review cycles address drift that metrics alone won’t catch. A monthly review of active context versions against current model behavior, current tool schemas, and current policy requirements catches misalignment before it becomes a user-facing problem. Pair this with automated alerts and thresholds for metric-detectable regressions and you have both reactive and proactive coverage.
For teams scaling AI agents, the BRDGIT guide on scaling AI agents covers how versioning discipline compounds in value as agent complexity grows. The cost of a missing review cycle scales with the number of agents sharing a context artifact.
10. Use promotion pipelines with approval gates between environments
Simultaneous context pushes without rollback controls are unsafe. A promotion pipeline enforces that every context version passes through development, staging, and production in sequence, with automated evaluation gates and human approval checkpoints between each stage.
The pipeline structure also creates a natural audit trail. Every promotion event is logged with who approved it, what evaluation scores it carried, and what version it replaced. When a compliance team or post-incident review asks what was running and who authorized it, the pipeline log answers both questions without any manual reconstruction.
Feature flags add a further layer of control by decoupling deployment from activation. You can deploy a new context version to production infrastructure without activating it for any users, then activate it for a defined segment when you’re ready to start the canary rollout.
Key takeaways
Effective AI context versioning treats every prompt, tool contract, and policy file as an immutable, versioned artifact managed through staged deployment pipelines with quality-based rollback controls.
| Point | Details |
|---|---|
| Immutability is non-negotiable | Published versions are never edited; all changes create a new version ID. |
| Version the full environment | Prompt, tool schemas, policy config, and model pin must all be versioned together. |
| Rollback is a pointer switch | Alias switching to a prior immutable version recovers production in seconds. |
| Canary rollouts use quality triggers | Format validity and semantic correctness scores, not just error rates, drive rollback decisions. |
| Monitoring requires golden datasets | LLM judges running against curated test cases catch regressions that infrastructure metrics miss. |
Why I think most teams underinvest in context versioning until it’s too late
I’ve watched teams build genuinely capable AI features and then lose weeks to a single untracked prompt edit that nobody could explain. The incident pattern is always the same: a developer makes a “small improvement” directly in a production config, behavior shifts in a way that’s hard to characterize, and the investigation stalls because there’s no record of what changed or when.
The cultural shift required is not primarily technical. Most developers already understand version control. The gap is that they don’t yet treat a system prompt with the same seriousness as application code. A prompt is not documentation. It is executable logic. Editing it in place is the equivalent of patching a binary in production.
Leadership has a specific role here. If the engineering culture treats context changes as low-stakes configuration work, developers will behave accordingly. When a CTO or technical lead explicitly classifies context artifacts as production code with the same review and deployment requirements, the team’s behavior changes quickly. The tooling follows the culture, not the other way around.
The other thing I’d push back on is the idea that you need a perfect versioning system before you start. A Git repository with a naming convention and a manual evaluation checklist is vastly better than nothing. Start there, add automation as you learn what your team actually needs, and treat the versioning practice itself as something you iterate on. The teams that wait for the perfect setup ship unversioned context to production for another six months.
For teams already using Claude in production, the webhook context update guide covers the mechanics of keeping versioned context in sync with live systems.
— Paul
How ClaudeDrive handles context versioning in production
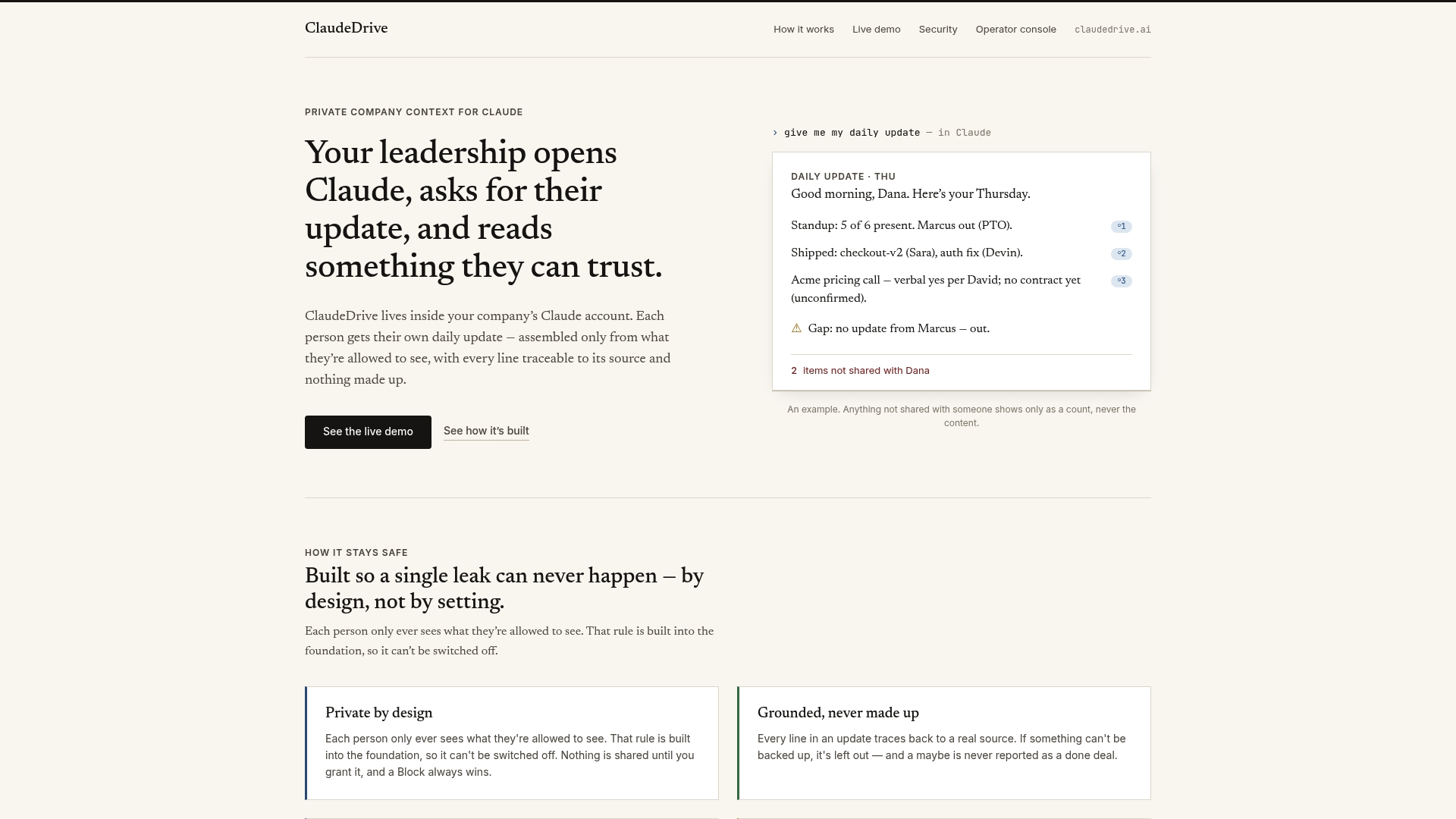
ClaudeDrive is the private context layer that feeds Claude with versioned, source-traced information from your existing tools. Every briefing Claude delivers is built from a controlled, auditable context snapshot. No untracked edits, no silent changes, no context that can’t be traced back to a specific source and a specific moment in time.
For technical leaders who want to see what disciplined context management looks like in practice, the ClaudeDrive Console gives you versioned context registries, rollout controls, and quality monitoring without a new platform to deploy. Connect your existing tools, define who sees what, and let Claude deliver updates your leaders can trust. Talk to us about a pilot.
FAQ
What is AI context versioning?
AI context versioning is the practice of managing prompt templates, tool contracts, and policy configurations as immutable, versioned artifacts with full deployment and rollback controls. It applies the same discipline as software version control to the instructions and configurations that drive AI behavior.
Why can’t you just edit a production prompt directly?
Editing a production prompt in place removes the ability to roll back quickly and destroys the audit trail. The standard practice is to treat published versions as immutable and create a new version ID for every change, so rollback is a fast pointer switch rather than a reconstruction effort.
What should you version beyond the prompt?
Minimum viable versioning covers prompt templates, tool schemas, policy configuration files, model version pins, and retrieval configuration. Omitting any of these creates silent behavior changes that are difficult to debug.
How do canary deployments work for AI context?
Canary rollouts start at 1% of traffic and scale through 5%, 20%, and 100% as quality metrics hold. Rollback triggers are quality-based: format validity rates, semantic correctness scores, and escalation rates rather than infrastructure error rates.
How do you detect context drift after deployment?
Continuous monitoring with golden datasets evaluated by LLM judges catches metric-detectable regressions. Scheduled monthly reviews of active context versions against current model behavior and tool schemas catch slower environment-driven drift that automated alerts miss.