How to Enforce Access Control at Retrieval: 2026 Guide
Learn how to enforce access control at retrieval effectively. Secure your data by applying authorization at the moment of access. Discover more!
ClaudeDrive
A Yungsten Tech product

How to Enforce Access Control at Retrieval: 2026 Guide

Access control enforcement at retrieval is defined as the practice of applying authorization decisions at the exact moment data is fetched, so only content a user is permitted to see ever enters the response. This is the standard the NIST identity framework and OWASP application security guidelines both point toward: authorization must happen at the data source, not after the fact. When security teams enforce access control at retrieval, they close the gap that post-retrieval filtering leaves open. A filter applied after data is pulled can still expose sensitive content through inference, logging, or downstream processing errors. The retrieval layer is the last reliable checkpoint before information reaches a user, and it is the right place to draw the line.
What does it take to enforce access control at retrieval?
The foundation is a working identity system. Every user, service account, and automated process needs a verified identity before any retrieval request is evaluated. Central directories such as Microsoft Entra ID or Okta serve as the source of truth for who is making a request and what attributes they carry.

Resource tagging is equally critical. Every document, record, or data asset needs metadata that describes its sensitivity level, owning team, and applicable access policy. Without that metadata, a policy engine has nothing to evaluate against. Tagging is not a one-time project. It requires ongoing governance as data is created, modified, and retired.
The tools that translate identity and resource metadata into runtime decisions fall into two categories:
- Policy-as-code engines: Tools like Open Policy Agent (OPA) and Cedar allow security teams to write authorization rules as versioned, testable code. Cedar and Rego policies scale authorization in multi-tenant environments and eliminate hardcoded permission errors that plague application-layer approaches.
- Externalized authorization platforms: AWS Verified Permissions and similar platforms sit outside the application and evaluate policies at runtime. They decouple authorization logic from application code, which makes updates and audits far simpler.
- Short-lived credentials: Workload identities backed by short-lived tokens reduce the blast radius of a compromised credential. If a service account token expires in minutes, a stolen credential has a narrow window of usefulness.
- API gateways with authorization hooks: Gateways intercept retrieval requests before they reach the data store and call the policy engine for a decision. This creates a consistent enforcement point regardless of which application initiates the request.
Pro Tip: Map every application role back to a central directory group before writing a single policy rule. Role mapping done upfront prevents the policy sprawl that makes audits painful later.
| Prerequisite | What it enables |
|---|---|
| Central identity directory | Single source of truth for user attributes and group membership |
| Resource metadata tagging | Policy engine can match user attributes to data sensitivity labels |
| Policy-as-code engine | Versioned, testable authorization rules evaluated at runtime |
| Externalized authorization platform | Decoupled policy decisions that scale without code changes |
| Short-lived workload credentials | Limits exposure window for automated retrieval processes |
How do you implement retrieval-layer access control step by step?
Implementation follows a clear sequence. Skipping steps creates gaps that are difficult to detect until a breach surfaces them.
-
Establish centralized policy management. Write all authorization rules in a policy-as-code language such as Rego or Cedar. Store policies in version control. This makes every change auditable and every rule testable before it reaches production.
-
Translate policy decisions into query-time filters. When a retrieval request arrives, the authorization engine evaluates the user’s attributes against resource metadata and returns a set of permitted document identifiers or metadata filter conditions. Runtime policy evaluation constructs these metadata filters on retrieval calls, so the data store only returns what the policy allows.
-
Apply deny-by-default logic. If the authorization service is unreachable or returns an error, the retrieval system must deny the request. Deny-by-default at retrieval ensures no unauthorized data leaks during fail-open scenarios. This is a non-negotiable design requirement.
-
Integrate authorization checks at the API gateway layer. The gateway intercepts every inbound retrieval request, calls the policy engine, and either passes the filtered query to the data store or returns an access-denied response. No request reaches the data store without a policy decision attached.
-
Automate role and permission lifecycle management. Central governance and automated periodic reviews of user permissions prevent drift as roles evolve. A quarterly manual review is not sufficient when staff changes, project assignments, and data classifications shift continuously.
-
Test retrieval filtering effectiveness. Run test queries as users with different permission levels and verify that results match expected access boundaries. Include negative tests: confirm that a restricted user receives zero results for content they should not see, not a partial or degraded result set.
The most common failure point is step three. Teams build the policy engine and the filters, then leave the failure mode as an open question. A system that fails open is a system that leaks data under pressure.
Pro Tip: Treat your vector database or document store with the same access control rigor you apply to a relational database. Vector databases as sensitive systems require fine-grained controls equal to any other data store holding sensitive records.

What are the common mistakes when restricting data access at retrieval?
Most retrieval security failures trace back to a small set of repeatable mistakes. Recognizing them before implementation saves significant remediation effort.
- Post-retrieval filtering treated as sufficient. Filtering results after they are returned from the data store does not prevent the data from being processed, logged, or cached. Authorization after retrieval is too late. Policy enforcement must happen at the data source.
- Hardcoded roles and permissions. Embedding role checks directly in application code creates a maintenance problem. Every role change requires a code deployment. Policy-as-code engines exist precisely to avoid this.
- Fail-open authorization. When the policy engine is unavailable, some systems default to allowing access rather than denying it. This is the wrong default. A retrieval system that cannot confirm authorization should never return data.
- Permission drift. Users accumulate access rights over time as they change roles, join projects, and inherit permissions from group memberships. Without automated reviews, the gap between what users are permitted to see and what they should be permitted to see widens steadily.
- Ignoring workload identity scopes. Automated pipelines and scheduled jobs carry their own identities. Those identities need scoped permissions just as human users do. A service account with broad read access is a significant risk if it is compromised.
Retrieval-layer authorization belongs in the identity control plane. Treating it as an application cleanup task after data is fetched leaves authorization gaps that are invisible until they are exploited. Security teams that close this gap by design, not by reaction, operate from a fundamentally stronger position.
Access control also requires collaboration. The Canadian Centre for Cyber Security guidance on access control states that security and privacy teams must work together with documented procedures to avoid privacy failures in automated environments. That collaboration is not optional when retrieval systems handle sensitive data at scale.
How do RBAC and ABAC integrate with retrieval-layer enforcement?
Role-based access control (RBAC) and attribute-based access control (ABAC) are the two dominant models for retrieval security, and they serve different needs.
RBAC assigns users to roles, and roles carry defined access rights. Mapping central directory roles to system roles and enforcing them in retrieval layers reduces complexity and risk. RBAC works well when access patterns are stable and the number of distinct roles is manageable. A finance team member gets access to financial records. An engineering lead gets access to technical documentation. The rules are clear and easy to audit.
ABAC evaluates policies dynamically using attributes of the user, the resource, and the request context. A policy written in Rego might grant access to a document only when the user’s department attribute matches the document’s owning department label and the document’s sensitivity level is below a defined threshold. ABAC policies evaluated externally enforce fine-grained retrieval filtering per request without requiring a new role for every combination of conditions.
| Model | Best suited for | Trade-off |
|---|---|---|
| RBAC | Stable, well-defined access patterns | Less flexible when conditions are complex or context-dependent |
| ABAC | Dynamic, attribute-driven access decisions | Higher policy complexity and testing overhead |
Most mid-sized organizations benefit from a hybrid approach. RBAC handles the baseline: who belongs to which team and what data categories that team accesses. ABAC handles the exceptions: time-of-day restrictions, sensitivity thresholds, and cross-team collaboration scenarios. The permission-aware AI updates model that ClaudeDrive uses reflects this hybrid logic, where identity-based policies and resource attributes combine to determine what each leader sees.
The key design principle for both models is the same: authorization decisions must be externalized from the application and evaluated at retrieval time. A policy that lives in application code is a policy that gets bypassed when the code is patched, forked, or replaced.
Key Takeaways
Retrieval-layer access control is the only reliable method to prevent unauthorized data exposure, because authorization applied after data is fetched cannot undo what has already been processed.
| Point | Details |
|---|---|
| Enforce at the source | Apply authorization decisions before data leaves the store, not after it is returned. |
| Use deny-by-default | If the policy engine fails, the retrieval system must deny access, never allow it. |
| Externalize policy logic | Write authorization rules in Cedar or Rego, outside application code, for auditable and testable control. |
| Automate permission reviews | Scheduled automated reviews prevent drift as roles and data classifications change over time. |
| Combine RBAC and ABAC | Use RBAC for stable access patterns and ABAC for dynamic, attribute-driven retrieval filtering. |
Why retrieval-layer enforcement is the security decision that actually matters
I have reviewed access control architectures at organizations that believed their data was protected because they had role definitions in their identity provider and filters in their application layer. In nearly every case, the gap was the same: authorization happened after retrieval, not before it. The data had already moved. The log had already been written. The inference had already been made.
The uncomfortable truth is that most access control failures are not caused by missing policies. They are caused by policies applied at the wrong layer. A well-written RBAC model that enforces permissions at the application display layer is not a retrieval security control. It is a presentation filter. Those are not the same thing.
The organizations that get this right treat the retrieval layer as a trust boundary, not a convenience layer. They write policies in code, version them, test them, and review them on a schedule. They build deny-by-default into the architecture from day one, not as an afterthought. And they involve both security and privacy teams in the design, because retrieval security is not purely a technical problem. It is a governance problem that happens to have a technical solution.
For IT and security leaders at mid-sized companies, the practical starting point is simpler than it sounds. Map your identities. Tag your resources. Pick a policy engine. Build the deny-by-default path first. Everything else follows from those four decisions. The auditing methods for AI updates that complement retrieval enforcement are a natural next step once the enforcement layer is in place.
— Paul
How ClaudeDrive handles retrieval-layer access control for leadership teams
ClaudeDrive is built on the principle that every leader should read only what they are permitted to see, with every line traceable to a real source.
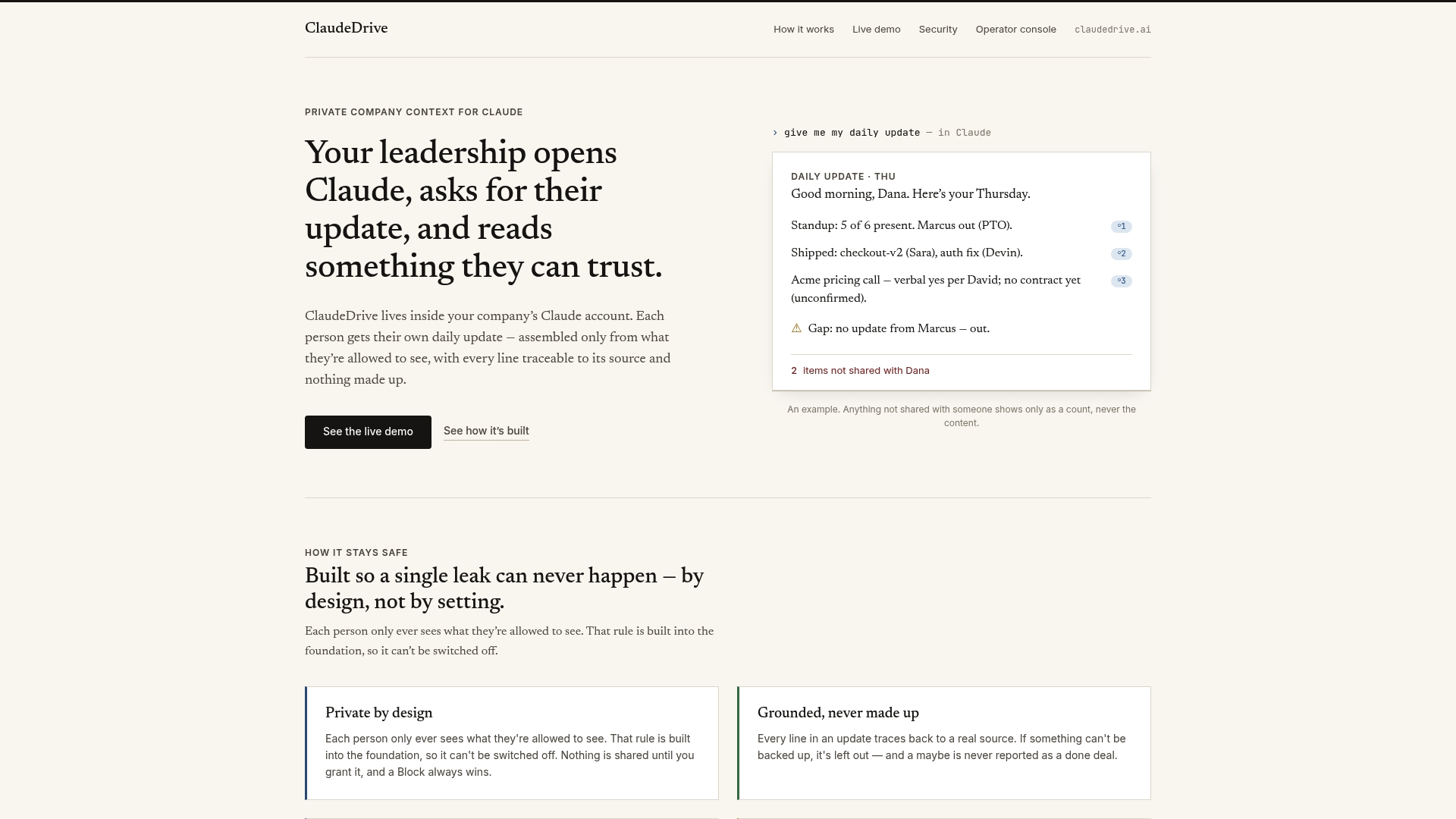
The ClaudeDrive Console connects to your existing tools, meeting notes, GitHub, and calendars, and applies identity-based policy filtering at retrieval time. Each person gets a private view of what happened, built from the data their role permits. Nothing leaks across team boundaries. No new dashboard to learn, no wiki to maintain. The deny-by-default architecture means that if a source cannot be verified against a user’s permissions, it does not appear in their briefing. Talk to us about a pilot and see how retrieval-layer enforcement works in practice for your leadership team.
FAQ
What does “enforce access control at retrieval” mean?
It means applying authorization decisions at the moment data is fetched from a source, so only permitted content is returned. No unauthorized data enters the response, the log, or any downstream process.
Why is post-retrieval filtering not sufficient for data security?
Post-retrieval filtering allows data to be fetched and processed before any restriction is applied. That creates exposure through logs, caches, and inference. Authorization must happen before retrieval, not after.
What is deny-by-default in retrieval authorization?
Deny-by-default means the retrieval system returns no data if the authorization service is unavailable or returns an error. It prevents fail-open scenarios where a system outage accidentally grants broad access.
How does ABAC differ from RBAC in retrieval enforcement?
RBAC assigns access based on a user’s role, while ABAC evaluates dynamic attributes of the user, the resource, and the request context. ABAC handles complex, conditional access rules that RBAC cannot express without creating an unmanageable number of roles.
How do you prevent permission drift in retrieval systems?
Automated periodic reviews of user permissions, combined with policy-as-code that is version-controlled and tested, prevent drift as roles and data classifications change. Manual quarterly reviews are not sufficient for environments where access patterns shift frequently.