Enterprise AI Update Delivery Explained for Leaders
Discover how enterprise AI update delivery explained ensures reliable upgrades. Learn methods for compliance and employee trust in AI systems.
ClaudeDrive
A Yungsten Tech product

Enterprise AI Update Delivery Explained for Leaders

Enterprise AI update delivery is the practice of managing AI system upgrades through phased rollouts, multi-agent orchestration, and governance controls to produce reliable, auditable, and predictable outcomes. For business leaders at high-growth companies, understanding this process is not optional. AI systems that update without structure create compliance gaps, erode employee trust, and produce outcomes no one can trace. Platforms like Rel(AI)Build from Happiest Minds and agentic frameworks from providers like Axiom Studio have made enterprise AI update delivery explained as a discipline, not just a technical task, a priority for executive teams in 2026.
What are the core methods for delivering enterprise AI updates?
Enterprise AI update delivery relies on three foundational methods: phased rollouts, multi-agent delivery frameworks, and environment isolation. Each method addresses a different failure point in the update process.
Phased rollouts treat traffic as a dial, not a switch. A structured phased rollout routes 10% of traffic on day one, scales to 25% by day three, and preserves a rollback option for at least 30 days after the update goes live. That window gives operations teams time to catch regressions before they reach the full user base.

Multi-agent delivery frameworks assign specialized agents to discrete tasks: one for requirements analysis, one for architecture review, one for testing. Multi-agent architectures clarify handoffs and embed human review at gate points between each stage. The result is a delivery chain where accountability is visible at every step.
Environment isolation separates staging, production, and rollback versions into distinct layers. Treating AI prompts as code and agents as production services means every change goes through the same review cycle as software. This is not a best practice reserved for large engineering teams. Any company running AI in a customer-facing or decision-support role needs this separation.
- Define the update scope and affected workflows before writing a single line of prompt or configuration.
- Deploy to a staging environment and run structured tests against known failure cases.
- Route a small traffic slice to the updated agent and monitor for output drift or error rate changes.
- Expand traffic incrementally, with a documented rollback trigger if key metrics degrade.
- Archive the prior version for at least 30 days and log every change with a traceable record.
Pro Tip: Treat every AI prompt change the same way you treat a code commit. Version it, review it, and never push it directly to production without a staging test.
How does governance enable trustworthy AI update delivery?
Governance is the layer that turns a working update process into a trustworthy one. Without it, even a technically sound rollout can violate data policies, exceed cost budgets, or leave no audit trail for compliance teams.
Governance frameworks for enterprise AI enforce six dimensions: identity verification, data classification, model selection controls, cost attribution, audit logging, and policy enforcement automation. Each dimension closes a specific gap. Cost attribution, for example, prevents a single team from consuming disproportionate compute resources without visibility from finance. Audit logging gives compliance officers a line-by-line record of what changed, when, and who approved it.
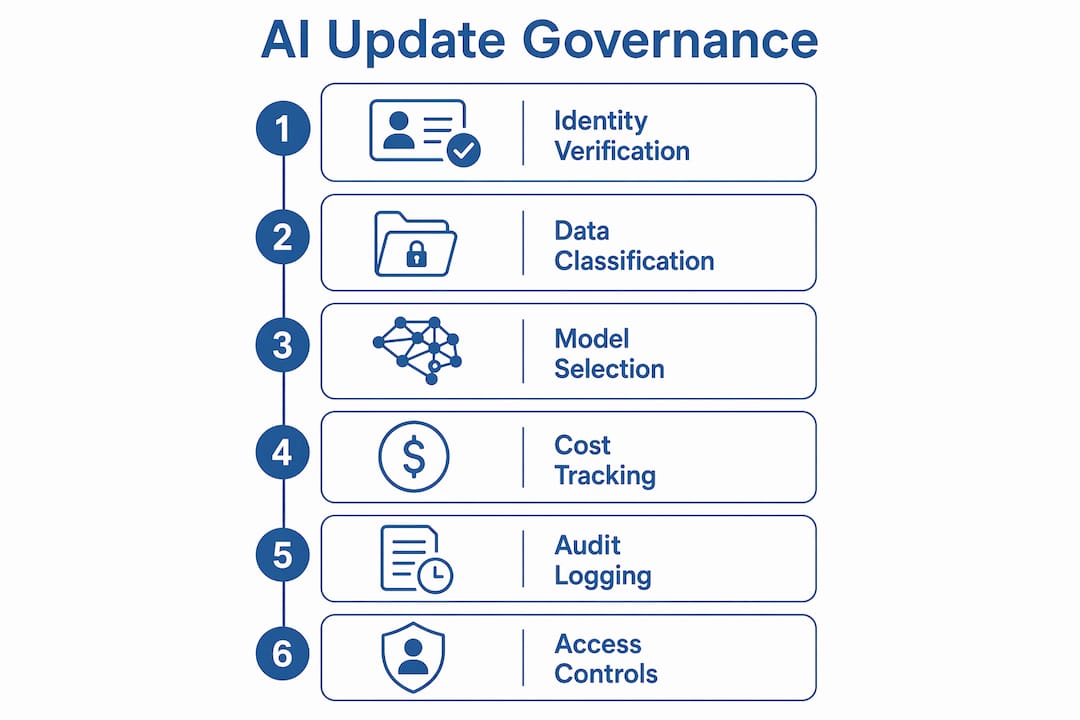
Hybrid deployment patterns address the tension between security and operational efficiency. Sensitive data operations run on a private VPC data plane while control functions run as SaaS. Most enterprises move to this pattern within the first year of running AI at scale, because it lets them meet data residency requirements without rebuilding their entire infrastructure.
Role-based access controls and scoped data access determine who sees what during an update cycle. A product manager reviewing rollout progress should not have the same view as a security engineer auditing model behavior. Scoped access enforces that boundary without requiring manual intervention every time a new team member joins a project.
“Without formal governance and change management, employee resistance and budget overruns limit AI adoption success.” This is not a warning for large enterprises only. High-growth companies face the same risks at smaller scale, and they often have less capacity to recover from a failed rollout.
Integration with legacy systems adds another layer of complexity. AI update delivery that works in isolation but breaks a CRM integration or a data warehouse pipeline creates more problems than it solves. Governance frameworks must account for upstream and downstream dependencies before any update reaches production.
For leaders who want to understand how auditing AI updates works in practice, the audit trail is the single most important artifact a governance process produces.
What benefits do structured update delivery frameworks deliver?
The business case for structured AI update delivery is concrete and measurable. Organizations using agentic AI platforms with structured development lifecycles achieve 40–60% faster modernization, threefold engineering productivity, and 30–50% lower support costs. Those numbers reflect what happens when update delivery stops being ad hoc and starts being a repeatable process.
Multi-agent orchestration cuts requirements-to-deployment cycle times by 35–50% compared to traditional methods. That compression comes from parallel workstreams, clear handoffs, and earlier detection of ambiguity in requirements. When a requirements agent flags a gap before the architecture agent starts work, the team avoids a rework cycle that would otherwise cost days.
| Metric | Traditional delivery | Structured AI delivery |
|---|---|---|
| Modernization speed | Baseline | 40–60% faster |
| Engineering productivity | Baseline | Up to 3x higher |
| Support costs | Baseline | 30–50% lower |
| Requirements-to-deployment cycle | Baseline | 35–50% shorter |
Improved software quality follows from the process, not from individual effort. When every update goes through staged deployment, structured testing, and a documented rollback plan, defect rates fall because the process catches problems before they reach users. Operational resilience improves for the same reason: a team that has practiced rollback knows exactly what to do when something goes wrong.
The competitive advantage is real but easy to misread. Faster delivery does not mean shipping more features. It means shipping the right changes with less risk, less rework, and more confidence that the system will behave as expected.
What practical steps should leaders take to implement AI update delivery?
Leaders do not need to run the technical process. They do need to set the conditions that make it work. Structured AI deployment requires a zero-DevOps model with automation, repeatable deployments, rollback capabilities, and versioned change management. The leader’s job is to demand that model and fund it before the first pilot launches.
- Map workflows before the pilot. Identify which business processes the AI update will touch and who owns each one. Governance gaps discovered after launch are far more expensive to fix.
- Adopt a phased rollout plan with a named rollback owner. Someone must be accountable for pulling the trigger on a rollback. That person and their criteria should be documented before day one.
- Embed human-in-the-loop checkpoints. Human-in-the-loop governance ensures approval paths, integration requirements, and operational ownership are clear before any agent goes live. Gate points between delivery stages are where leadership oversight has the most leverage.
- Implement monitoring dashboards tied to business metrics. Error rates and latency matter to engineers. Outcome quality, cost per transaction, and user trust matter to leaders. Both views need to be visible.
- Communicate the update plan to affected teams. Employee resistance is a documented cause of AI adoption failure. A clear briefing on what is changing, why, and what the rollback plan is reduces resistance before it starts.
- Centralize update status and audit records. Leaders who rely on scattered Slack threads and email chains to track rollout progress will always be behind the facts. A single source of truth for update status is not a luxury.
Pro Tip: Before any AI update goes to staging, write a one-page brief that names the change, the business reason, the rollback trigger, and the person responsible. If you cannot write that brief in under 30 minutes, the update is not ready.
Understanding filtered AI delivery for leadership is one way to see how these principles translate into a daily operating rhythm for executive teams.
Key Takeaways
Structured enterprise AI update delivery produces faster, safer, and more auditable outcomes than ad hoc approaches, and leaders who govern the process before launch avoid the rework and resistance that derail most AI projects.
| Point | Details |
|---|---|
| Phased rollouts reduce risk | Start at 10% traffic, scale to 25%, and keep a 30-day rollback window for every update. |
| Governance covers six dimensions | Identity, data classification, model use, cost tracking, auditing, and policy enforcement must all be addressed. |
| Multi-agent frameworks cut cycle time | Structured handoffs and parallel workstreams reduce requirements-to-deployment time by 35–50%. |
| Leaders must own the process | Governance gaps discovered after launch cost far more to fix than those caught before the pilot. |
| Centralized audit trails build trust | A traceable record of every change is the foundation of compliance and employee confidence. |
What I’ve learned about AI update delivery that most guides skip
Most writing on enterprise AI deployment focuses on the technical architecture. The harder problem is organizational. Leadership teams consistently underestimate how much process redesign an AI update requires, and they consistently overestimate how much the technology will handle on its own.
The pattern I see most often: a team ships an AI update with strong engineering discipline but no clear owner for the business workflow it touches. The update works technically. The business outcome degrades anyway, because no one mapped the handoff between the AI agent and the human process it was supposed to support. That gap does not show up in a monitoring dashboard. It shows up three months later in a support ticket backlog or a compliance audit.
The other underappreciated risk is hero dependency. When one engineer or one team lead is the only person who knows how to roll back an update, the organization is one resignation or sick day away from a serious incident. A zero-DevOps model with documented, repeatable rollback procedures eliminates that single point of failure. It is not glamorous work. It is the work that makes everything else reliable.
Hybrid deployment patterns are worth adopting earlier than most companies plan. The compliance benefits are obvious, but the operational benefit is less discussed: a hybrid model forces a clean separation between what the AI controls and what the business controls. That separation makes governance conversations much easier, because the boundary is architectural, not just policy.
The future of this space is automated lifecycle management, where agentic platforms handle dependency upgrades, test mapping, and rollback triggers with minimal human intervention. That future is closer than most leaders realize. The companies that will benefit most are the ones that have already built the governance muscle to know when to trust the automation and when to override it.
— Paul
How ClaudeDrive gives leaders a trusted view of AI update delivery
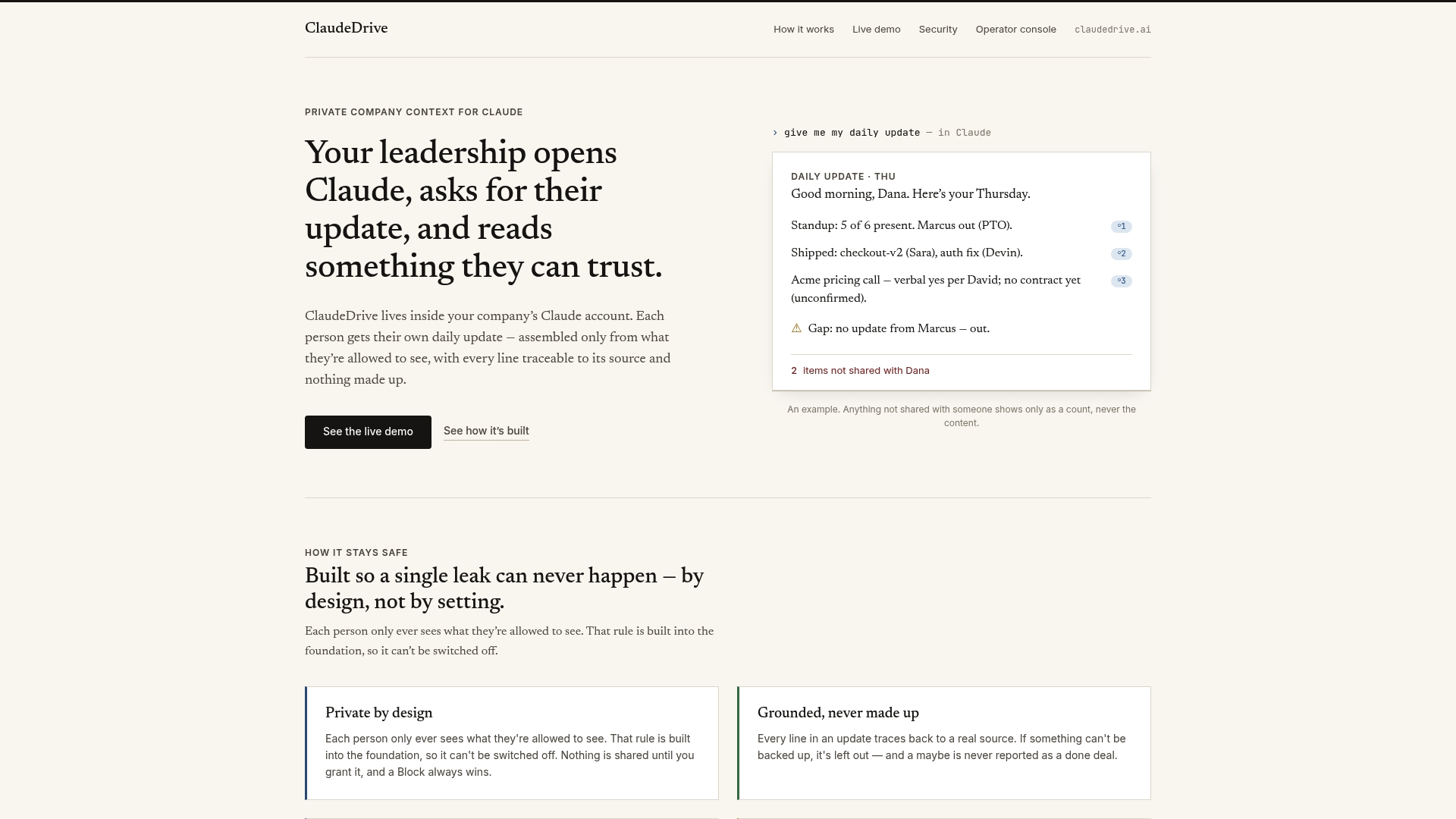
ClaudeDrive connects to the tools your teams already use, including meeting notes, GitHub, and your calendar, and delivers one clear briefing to each leader inside the Claude account they already have. Every line in that briefing traces back to a real source. Nothing is made up, and nothing crosses a data boundary it should not. For leaders overseeing AI update rollouts, that means rollout status, governance checkpoints, and team activity are visible in a single daily read, without a new dashboard to learn or a wiki to maintain. ClaudeDrive is the private company-context layer that feeds Claude. See the live demo or talk to us about a pilot.
FAQ
What is enterprise AI update delivery?
Enterprise AI update delivery is the structured process of releasing AI system changes through phased rollouts, governance controls, and multi-agent orchestration. The goal is reliable, auditable, and reversible updates at scale.
How does a phased rollout work for AI updates?
A phased rollout routes a small percentage of traffic, typically 10% on day one, to the updated AI system before expanding further. A 30-day rollback window is maintained so teams can revert if output quality or error rates degrade.
Why do enterprise AI updates need governance frameworks?
Governance frameworks enforce identity, data classification, cost tracking, and audit logging across every update cycle. Without them, updates can violate data policies, exceed budgets, or leave no record for compliance review.
How much faster is structured AI delivery than traditional methods?
Organizations using agentic platforms with structured delivery lifecycles achieve 40–60% faster modernization and reduce requirements-to-deployment cycle times by 35–50% compared to traditional approaches.
What is the leader’s role in AI update delivery?
Leaders set governance requirements, fund the process before the pilot launches, and demand a named rollback owner for every update. The technical execution belongs to the team; the operating model belongs to leadership.